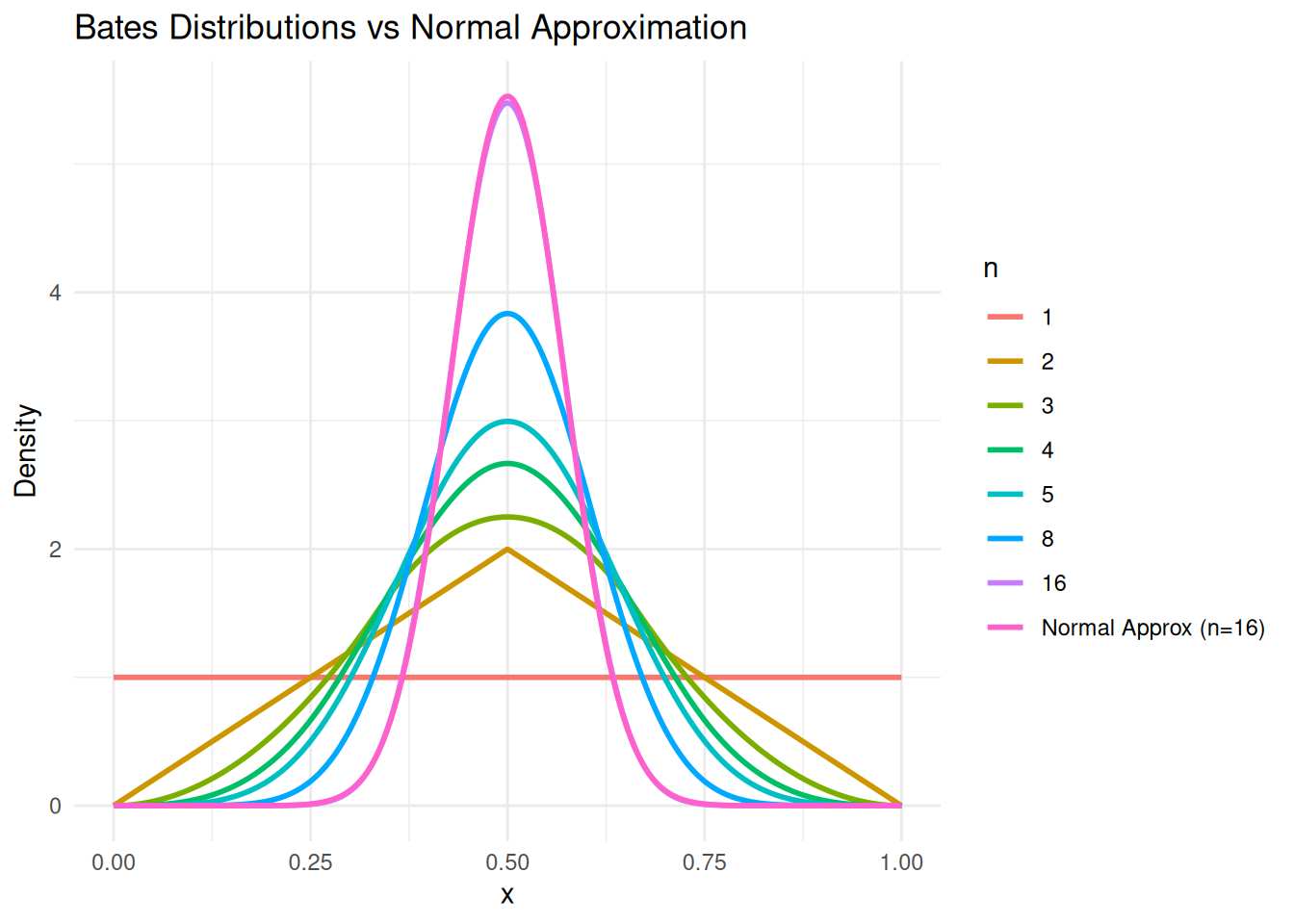
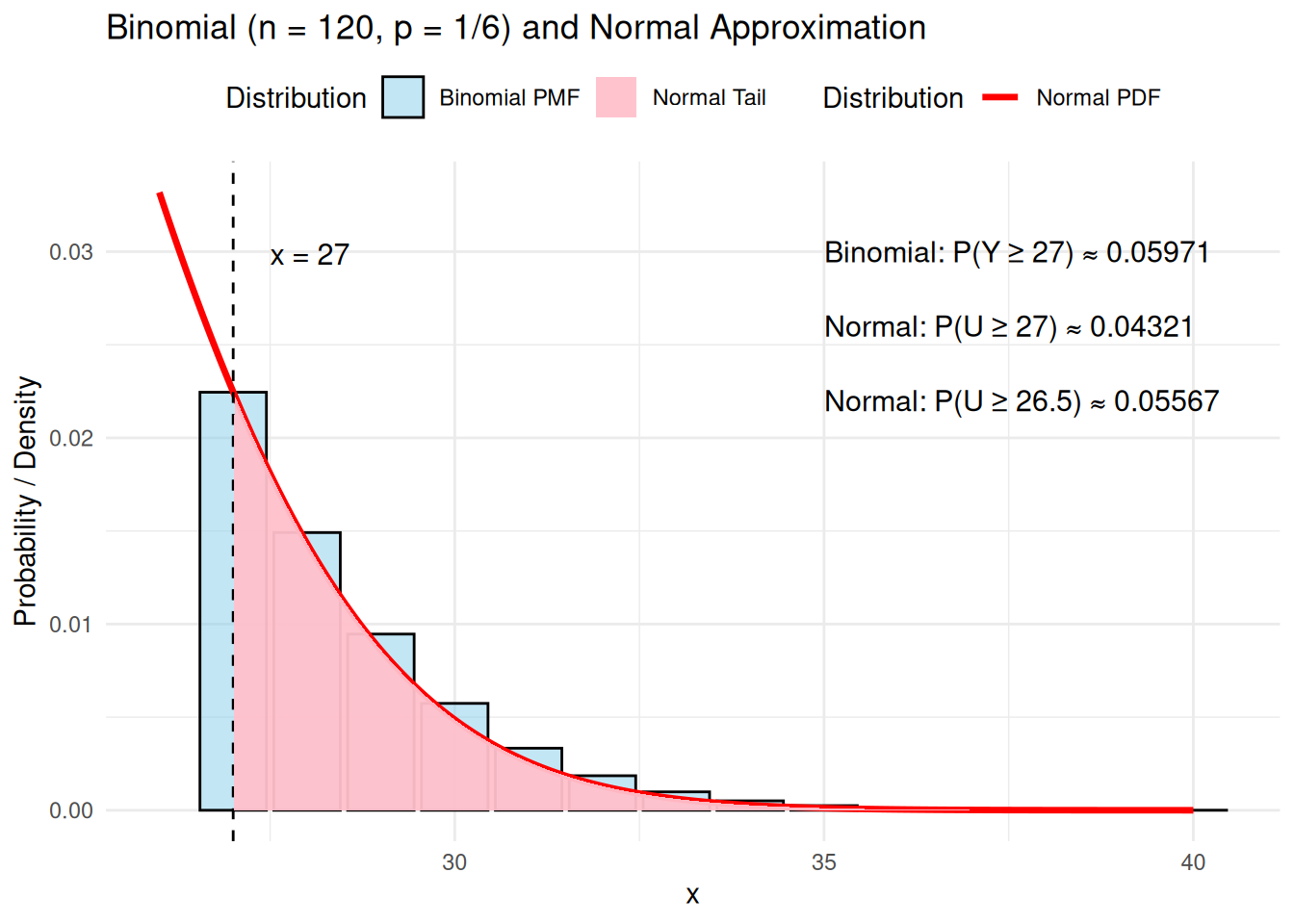
Proof (Lemma 1). The joint distribution of \(Y_1, Y_2, \ldots, Y_n\) is \[f_Y(y_1, y_2, \ldots, y_n) = \frac{1}{(2\pi)^{\frac{n}{2}}\sigma^n} exp \left\{ -\frac{1}{2} \sum_{i = 1}^n \left( \frac{y_i - \mu}{\sigma} \right)^2 \right\}\] Transform the random variables, \(Y_i, i = 1,2, \ldots , n\) to \[
\begin{align*}
X_1 &= \overline{Y} & \quad \overline{Y} &= X_1 \\
X_2 &= Y_2 - \overline{Y} & \quad Y_2 &= X_2 + X_1 \\
X_3 &= Y_3 - \overline{Y} & \quad Y_3 &= X_3 + X_1 \\
\vdots &\;= \vdots & \quad \vdots &= \vdots \\
X_n &= Y_n - \overline{Y} & \quad Y_n &= X_n + X_1
\end{align*}
\]
Then, the pdf is found through using the Jacobian of the transformation. In this context, the Jacobian (mapping from \(X\) to \(Y\) as we want to find the joint distribution of \(X\) and segregated it as suggested above) is, \[
[J_{ij}] = \left[\frac{\partial (Y_1, Y_2, \ldots Y_n)}{\partial (X_1, X_2, \ldots, X_n)}\right] = \begin{bmatrix}
\frac{\partial Y_1}{\partial X_1} & \frac{\partial Y_1}{\partial X_2} & \cdots & \frac{\partial Y_1}{\partial X_n} \\
\frac{\partial Y_2}{\partial X_1} & \frac{\partial Y_2}{\partial X_2} & \cdots & \frac{\partial Y_2}{\partial X_n} \\
\vdots & \vdots & \ddots & \vdots \\
\frac{\partial Y_n}{\partial X_1} & \frac{\partial Y_n}{\partial X_2} & \cdots & \frac{\partial Y_n}{\partial X_n} \\
\end{bmatrix} = \begin{bmatrix}
1 & -1 & -1 & \cdots & 1 \\
1 & 1 & 0 & \cdots & 0 \\
1 & 0 & 1 & \cdots & 0 \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
1 & 0 & 0 & \cdots & 0 \\
\end{bmatrix}
\]
Now, it only remains to find the determinant of \(J\). First, use row operations to achieve the following form, \[
J \sim \begin{bmatrix}
1 & -1 & -1 & \cdots & -1 \\
0 & 2 & 1 & \cdots & 1 \\
0 & 1 & 2 & \cdots & 1 \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
0 & 1 & 1 & \cdots & 2 \\
\end{bmatrix}
\]
Therefore, we only need find the determinant of the bottom right \((n-1) \times (n-1)\) sub-matrix, \[
\lvert B\rvert \triangleq
\left\lvert
\begin{bmatrix}
2 & 1 & \cdots & 1 \\
1 & 2 & \cdots & 1 \\
\vdots & \vdots & \ddots & \vdots \\
1 & 1 & \cdots & 2 \\
\end{bmatrix}
\right\rvert
\]
Now, the easiest way is to realise the following, \[
B = 2I_{n-1} + (\mathbf{1}\mathbf{1}^\top - I_{n-q}) = I_{n-1} + \mathbf{1}\mathbf{1}^\top
\] as a special case of the householder matrix.
Then, we realise the following eigendecompositions,
- \(\mathbf{1} = \begin{bmatrix} 1 & 1 & \cdots & 1 \end{bmatrix}^\top\) is an eigen-vector of \(\mathbf{1}\mathbf{1}^\top\) with eigen-value \(n-1\).
- Other orthogonal vectors to \(\mathbf{1}\) would also be eigenvectors, but with eigenvalues of 0. We generally have \(n - 1\) linearly independent such vectors. One example set is by considering using \(\{ \mathbf{e}_j - \mathbf{e}_1 \}\).
Therefore, \(B\) has eigenvalues, \[
\lambda_1 = 1 + (n - 1) = n, \qquad \lambda_2 = \cdots = \lambda_{n-1} = 1
\]
Hence, \[
\det B = n \cdot 1^{n-2} = n
\]
Therefore, \(\lvert J \rvert = n\). Now, with a bit of detour, we know the pdf of joint distribution of \(Y_1, Y_2, \ldots , Y_n\) is \[
\begin{align}
f_{X_1, X_2, \ldots , X_n}(x_1, x_2, \ldots , x_n) &= f_Y(y_1, y_2, \ldots, y_n) \lvert J \rvert \\
& = n f_X(y_1, x_1 + x_2, \ldots, x_1 + x_n) \\
& = \text{constants} \cdot \exp \left\{ -\frac{1}{2} \sum_{i=1}^n \left( \frac{y_i - \mu}{\sigma} \right)^2 \right\}
\end{align}
\] Now, something similar comes up again as above… \[
\begin{align}
\sum_{i=1}^n \left( \frac{y_i - \mu}{\sigma} \right)^2 & = \frac{1}{\sigma^2} \sum_{i=1}^n (y_i - \mu)^2 \\
& = \frac{1}{\sigma^2} \left[ (y_1 - \overline{y})^2 + \sum_{i=2}^n (y_i - \overline{y})^2 + n(\overline{y} - \mu)^2 \right]
\end{align}
\] Note that since \(\sum_{i = 1}^n(y_i - \overline{y})\), it follows that \[
y_1 - \overline{y} = - \sum_{i=2}^n (y_i - \overline{y})
\]
Therefore, the above simpliifies to
\[
\begin{align}
\sum_{i=1}^n \left( \frac{y_i - \mu}{\sigma} \right)^2 & = \frac{1}{\sigma^2} \left[ \left( \sum_{i=1}^n (y_i - \overline{y}) \right) ^2 + \sum_{i = 2}^n (y_i - \overline{y})^2 + n(\overline{y} - \mu)^2 \right] \\
& = \frac{1}{\sigma^2} \left[ \left( \sum_{i = 2}^n x_i \right)^2 + \sum_{i=2}^n x_i^2 + n(x_1 - \mu)^2 \right] \\
\end{align}
\]
Therefore, the pdf of \(X_1, X_2, \ldots, X_n\), simplifies to \[
\begin{align}
f_{X_1, X_2, \ldots, X_n}(x_1, x_2, \ldots , x_n) & = \text{constants} \cdot \exp \left\{ -\frac{1}{2\sigma^2} \left[ \left( \sum_{i=2}^n x_i \right)^2 + \sum_{i=2}^n x_i^2 + n(x_1 - \mu)^2 \right] \right\} \\
& \propto \exp \left\{ \frac{1}{2\sigma^2} \left[ \left( \sum_{i=1}^n x_i \right)^2 + \sum_{i=2}^n x_i^2 \right] \right\} \exp \left\{ -\frac{n}{2\sigma^2} (x_1 - \mu)^2 \right\} \\
& \propto h(x_2, x_3, \ldots , x_n) \cdot g(x_1) \\
\end{align}
\]
Now, this follows with \(X_1\) being independent of \(X_2, \ldots, X_n\) as their joint probability distribution can be factored into a product of functions that depend only their repsectie set of statistics. Therefore, \(X_1 = \overline{Y}\) is independent of \(X_i = Y_i - \overline{Y}\), \(i = 2, 3, \ldots, n\).
Finally, since \(Y_1 - \overline{Y} = -\sum_{i=2}^n (Y_i - \overline{Y})^2\), it follows that \(Y_1 - \overline{Y}\) is a function of random variables that are independent of \(X_1 = \overline{Y}\), and so indpendent to \(X_1\).